
Last week at DPLAFest in Washington, DC, executive director Dan Cohen announced that the Digital Public Library of America had grown in its third year to include more than 13 million records. We’re proud to announce that 12,876 of those records were contributed by the University of Scranton Weinberg Memorial Library.
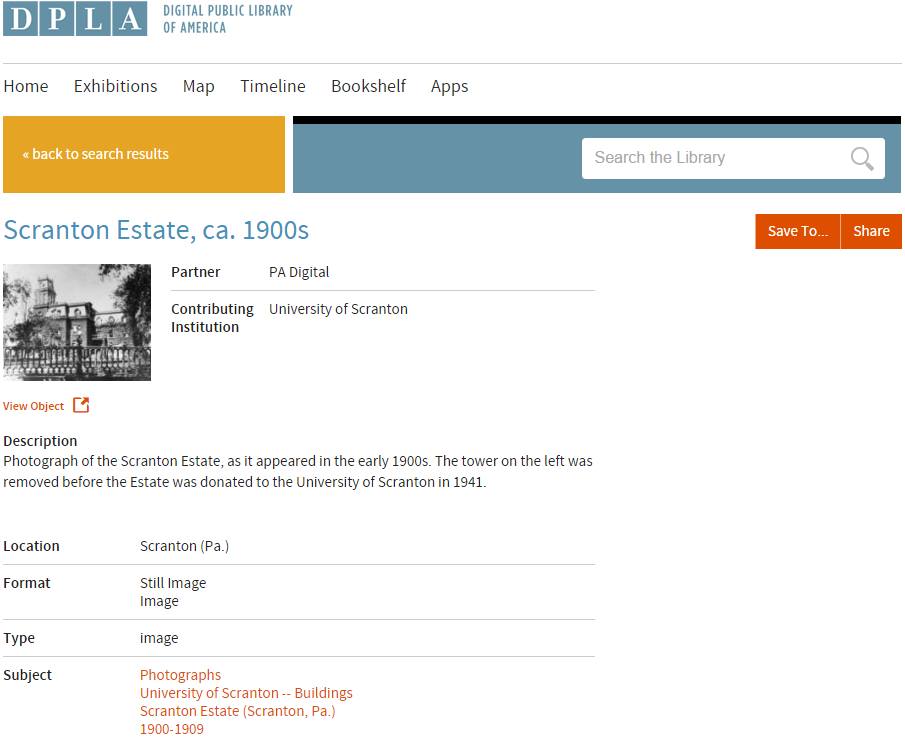
Launched in 2013, DPLA is a digital platform and network that brings together descriptive information for rare and unique digital materials from more than 1,900 libraries, archives, and museums across the country. It’s a portal to the treasures of American cultural heritage, from digitized photographs, films, documents, and objects to born digital ebooks, video, and images. All of these materials are freely available on the web for use by researchers, students, teachers, genealogists, and the general public.
We’ve been building digital collections at the University of Scranton since 2008, and nearly all of our materials are already publicly available on our website at www.scranton.edu/library/digitalcollections (some items are restricted due to copyright, privacy, or donor request). So why participate in DPLA?
DPLA doesn’t host digital materials – they’re all stored and made accessible by contributing institutions like us, so it’s still our job to keep digitizing, describing, preserving, and publishing digital items. What DPLA does is make these materials discoverable and usable in entirely new and exciting ways. Metadata records (descriptive information) that we send to DPLA are aggregated into a stream of open data that can be used by software developers and others to create new tools or visualizations. Two of our favorites are the DPLA Visual Search Prototype and Culture Collage, which offer more visual interfaces for browsing and sorting through search results.
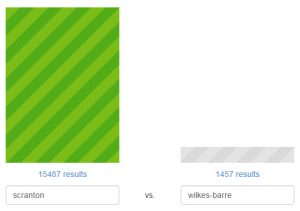
(We also get a kick out of Term vs. Term, which compares the number of DPLA search results for two phrases. You know, like Scranton vs. Wilkes-Barre. Just saying.)
 Perhaps most importantly, DPLA allows for unified access, which is important both for 1) users who don’t necessarily know what institution will have the records they’re looking for and 2) collections that have been physically fragmented across different institutions.
Perhaps most importantly, DPLA allows for unified access, which is important both for 1) users who don’t necessarily know what institution will have the records they’re looking for and 2) collections that have been physically fragmented across different institutions.
An example of the former might be a genealogist looking for information about family members from Scranton. Using DPLA, they can find not only relevant materials in our collections (like our yearbooks and Aquinas issues, which are excellent sources for information about our alumni) but they’ll also stumble across photographs, manuscripts, and books from the Lackawanna Valley Digital Archives, postcards from the Boston Public Library, stereographs and menus from the New York Public Library, and genealogical books from the Library of Congress.
An example of the latter is the Horace G. Healey Collection, an impressive set of 19th century penmanship and calligraphy. Half of the collection is available here on campus in our McHugh Special Collections (as part of our Zaner-Bloser Penmanship Collection), but the other half is at the New York Public Library. In DPLA, images of the artwork are reunited as they are digitized.
Our participation in DPLA has been in the works for almost two years. DPLA is unable to accept metadata records directly from individual libraries – there are just too many potential contributors! – so almost all of its data passes through nodes called Service Hubs. Most service hubs are established at a state or regional level, and Pennsylvania didn’t have one when DPLA first launched. Beginning in August 2014, a group of Pennsylvania cultural heritage institutions got together to discuss how best to collaborate on digital collections in the state. After a year of planning, coordination, and tons of work, the PA Digital Partnership was approved as a DPLA Service Hub in August 2015. On April 13, 2016, data from the PA Digital Partnership went live in DPLA, with 131, 651 records from 19 contributing Pennsylvania institutions.![]() We’re incredibly proud to be part of DPLA and the PA Digital Partnership, and we’re thrilled to see our digital collections be more accessible and discoverable than ever. Congratulations to all our PA Digital colleagues, and happy searching to all!
We’re incredibly proud to be part of DPLA and the PA Digital Partnership, and we’re thrilled to see our digital collections be more accessible and discoverable than ever. Congratulations to all our PA Digital colleagues, and happy searching to all!
We had a related idea on of our hackathons. We intended to automate creation of augmented reality based on historical scenes. That seems to be a popular idea these days: http://www.edutopia.org/blog/augmented-reality-new-dimensions-learning-drew-minock .
I think I would go both more hi-tech, but also more low-tech in some sense, for example, automated creation of coloring pages based on a historical material, something like these images http://colorkid.net/coloring-pages-architecture/coloring-pages-ancient-world
I am yet to think of an exact algorithm to do it.